● Enterprise AI Diagnostics
Your AI assistant isn't broken. Your retrieval is.
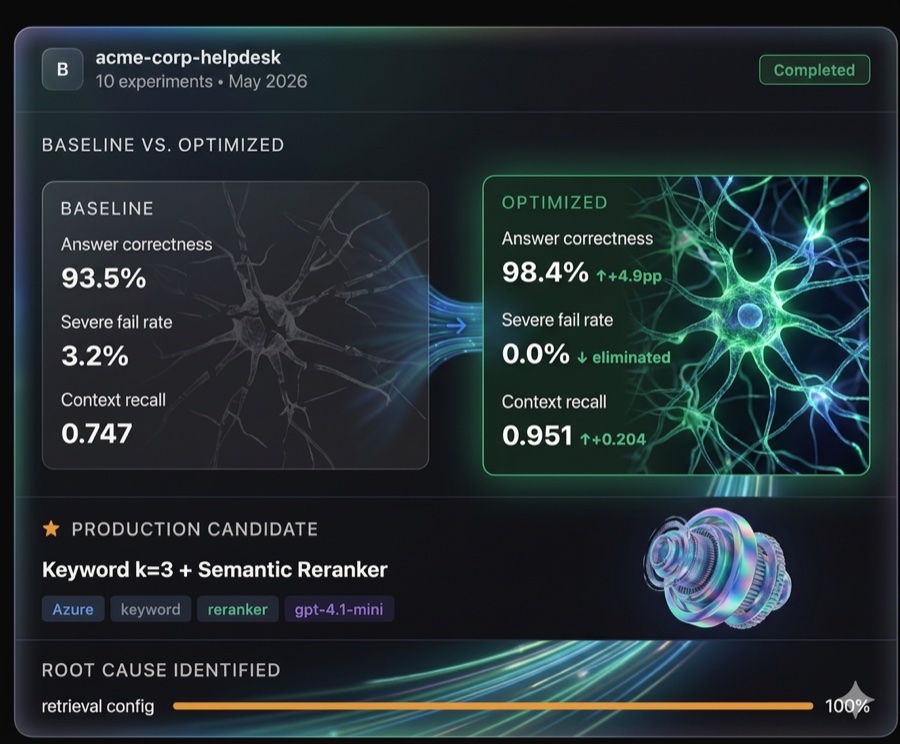
We connect to your existing search index — Azure AI Search, Amazon Bedrock Knowledge Bases, or Vertex AI Search — run a controlled experiment matrix, and deliver a ranked report showing which retrieval configuration produces the best answers on your actual data.
No implementation. No infrastructure changes. Just a measurement.